There are different options for parsing data in Microsoft Sentinel. Query time parsing when the parsing is done when an analytic or analyst executes a piece of KQL or Ingest time parsing when the data is parsed into a normalised structure at ingestion into Log Analytics.
Query time parsing
Microsoft Sentinel can use both query time and ingest time normalization.
Normalizing using query time parsing using Azure functions has several advantages:
- Preserving the original format: Query time normalization doesn’t require the data to be modified, thus preserving the original data format sent by the source.
- Avoiding potential duplicate storage: Since the normalized data is only a view of the original data, there is no need to store both original and normalized data.
- Easier development: Since query time parsers present a view of the data and don’t modify the data, they are easy to develop. Developing, testing and fixing a parser can all be done on existing data. Moreover, parsers can be fixed when an issue is discovered and the fix will apply to existing data.
Ingest time parsing
While you can optimize query time parsers, query time parsing can slow down queries, especially on large data sets.
Ingest time parsing enables transforming events to a normalized schema as they are ingested into Microsoft Sentinel and storing them in a normalized format. Ingest time parsing is less flexible and parsers are harder to develop, but since the data is stored in a normalized format, offers better performance.
Normalized data can be stored in Microsoft Sentinel’s native normalized tables, or in a custom table that uses an ASIM schema.
Advantages of Ingest parsing include:
- Better performance: Better performance all around. Ask yourself “Are the Microsoft supplied data tables such as the Defender tables in a normalised structure or do they use query parsers”. Microsoft puts its data in a normalised structure, parsed at ingestion.
- Better performance with fields in where clauses: Can improve this in query time parsing if you use parameterised queries but this is another item all the analysts need to know how to utilise.
- More options for filtering data: Filter out data as it is ingested, dropping sections of the raw message you do not need not need to pay ingestion or retention costs. Rule of thumb is 25% of any message could be dropped as unneeded for analytics or investigation work and reducing ingestion/retention costs by 25% is a good idea.
- Easier to structure queries: An analyst knows where the data is in a table, they do not have to worry about an inefficient query inside an Azure function.
In Summary
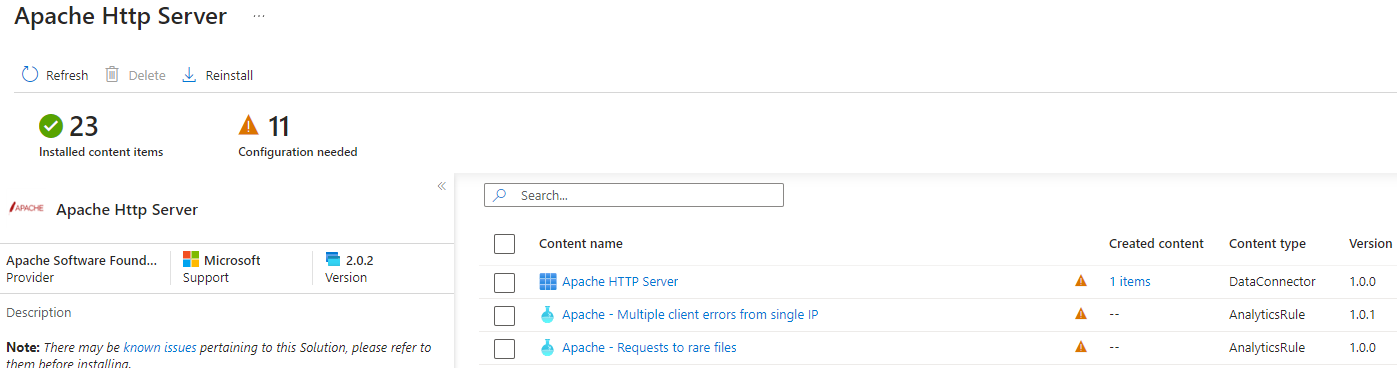
Whether you use Ingest or query time parsing, if you use parsers from Data Connectors or an online code repository do not just enable them by default. Analyse the column naming structures and adjust to meet your organisations naming schema, be it ASIM or other schema. Does the supplied parser miss rows or sections of rows? Does the data connector ingest data into an existing occupied table which has retention settings for another feed and would ingesting new data into that table cause cost issues? In the example below the Apache Data Connector on the content hub only matches with GET or POST methods and doesnt account for custom Apache log formats.

As a previous database administrator I have been trained to optimize data being ingested, have normalised tables and optimised queries. I like to know where my data is and how it is structured and dont like it to change so I prefer Ingest time parsing (as Microsoft does with its supplied tables)
Food for thought
Microsoft doesnt supply any form of unique index for its log analytics tables which could prevent you from ingesting duplicate data and occuring unnessecary ingestion/retenion costs.
Microsoft charges you for any data dropped by a DCR rule above 50% of the original data (albeit some unclear caveats in regards to Sentinel transformation filters). This is OK and not surprising as you cannot expect Microsoft to waste CPU cycles and bandwidth deleting or dropping mass amounts of customers data when they could make money by ingesting it.
Microsoft also provides a purge API to delete data based on KQL queries but as their official documentation shows this is ONLY for GDPR purposes and Microsoft reserve the right to reject any non-GDPR related purges…..why have a purge feature but prevent customers from using it…why stop your customers from reducing retention costs?